
개요
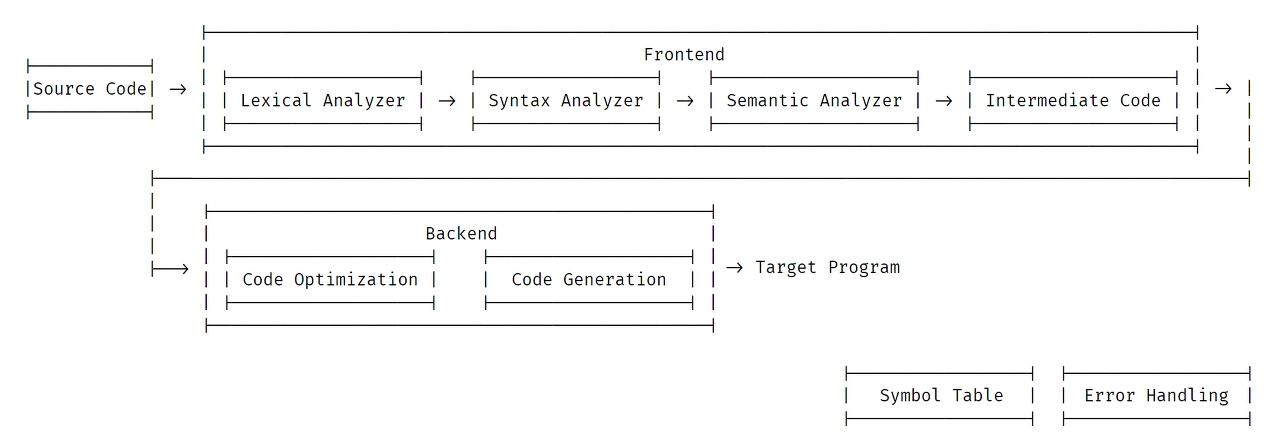
Source Code (소스 코드)
사용자의 소스 코드입니다. 아직 아무런 단계를 거치지 않았습니다.
Lexical Analyzer (어휘 분석기)
흔히 렉서(Lexer)라고도 불리며, 토큰까지 포함하여 토크나이저(Tokenizer)라고 불리기도 합니다.
Syntax Analyzer (구문 분석기)
흔히 파서(Parser)라고도 불리며, 이 과정(Parsing)을 통해 AST(Abstract Syntax Tree)를 생성합니다.
이 과정에서 문법이 결정되며, 흔히 Syntax Error 같은 오류 메세지는 이곳에서 발생합니다.
Lexer와 더불어 가장 기본적인 단계이며, 인터프리터 또한 이 과정을 가지고 있습니다.
Semantic Analyzer (의미 분석기)
후술하겠지만 심볼 테이블(Symbol Table)에서 데이터 등을 이용하여 소스코드가 유효한지 검사합니다.
가장 큰 기능은 타입 체킹(Type Checking)이며, 흔히 Type Error 같은 오류 메세지는 이곳에서 발생합니다.
그 외 아래와 같은 기능들을 합니다:
- 변수, 함수 등의 정의 여부 체크 (이 과정에서 Name Error 같은 오류 메세지를 만날 수 있습니다.)
- 데이터 타입 검사
- 의미 검사 (예를 들어
정수 + 문자열이라는 식이 있을때, 이것이 유효하지 않은 표현식으로 판단합니다. 이는 데이터 타입 검사에서 처리하기도 합니다.)
다만 이 과정은 완벽하지 않습니다.
Intermediate Code (Generator)
흔히 중간 표현(IR)이라고 하며, 의미 분석 과정을 거친 코드가 만들어지는 단계입니다.
이 코드가 최종적으로 컴파일될 코드입니다.
즉, 소스 코드와 기계어(최종 언어) 사이의 추상화된 언어라 생각하시면 됩니다.
Code Optimization
이제부터 백엔드(Backend) 단계에 왔으며, 이 단계부턴 CS(Computer Science)에 대해 어느정도 지식이 있어야 합니다.
이 과정에서 생성된 중간 표현(IR) 코드를 최적화하며, 이 단계에서도 총 3단계 까지 나눌 수 있습니다:
- HIR (High-Level Intermediate Representation): 소스 코드와 가장 가까운 수준이며, 전반적인 최적화를 위해 생성된 IR 코드입니다.
- LIR (Low-Level Intermediate Representation): 이제부터 소스 코드와 거리가 멀어지며, 아키텍쳐 같은 명령어들이 포함되어 있는 코드입니다.
- MIR (Machine-Level Intermediate Representation): 최종적으로 생성될 코드와 유사한 코드이며, 로우 레벨 관련으로 구체화 되어있습니다.
이 과정을 거쳐, 최종적으로 MIR에서 기계어 코드를 생성하며(Code Generator), 의미 분석기와 더불어 언어의 컴파일 시간, 실행 시간 등의 성능에 큰 영향을 미칩니다.
Target Program (대상 프로그램)
최종적으로 각각의 아키텍쳐에 맞춰 프로그램이 생성됩니다.
프로그램을 생성하는 과정을 거치지 않고, 따로 가상 머신(또는 ByteCode)을 만들어, 가상 머신 위에서 프로그램을 실행하기도 합니다.
JVM을 사용하는 자바나 코틀린(코틀린의 경우 Kotlin Native를 통해 아키텍쳐에 맞춰 기계어를 생성할 수 있습니다.)이 그 예시입니다.
Symbol Table (심볼 테이블), Error Handling (오류 처리)
심볼 테이블(Symbol Table)은 위에서 간단히 설명했는데, 프론트엔드, 백엔드 등의 과정에서 필요한 데이터 등을 포함하고 있는 테이블입니다.
오류 처리(Error Handling)는 Parsing Error (Syntax Error), Compile Error와 같은 오류 처리를 위해 존재합니다.